When AI Attacks AI: The McKinsey Lilli Hack and Agentic AI Security
On February 28, 2026, a fully autonomous AI agent pointed itself at McKinsey & Company's internal AI platform, Lilli, and within two hours had read-write access to the production database. No credentials. No insider help. No human at the keyboard. The haul: 46.5 million chat messages covering strategy, M&A talks, and client engagements. 728,000 files. 57,000 employee accounts. And — the part that should keep any AI platform owner up at night — writable system prompts for all 95 of Lilli's AI model configurations.
The vulnerability? SQL injection. A technique documented in 1998. Twenty-eight years later, it's still breaching enterprise AI platforms.
I've been covering agentic AI and identity security on this blog — the Microsoft Entra Agent ID deep-dive and the broader sovereignty conversation around where AI workloads run and who controls them. The McKinsey Lilli incident is exactly the kind of real-world event that crystallises why that work matters. So I want to talk through what happened, why agentic AI creates qualitatively different security challenges, and what the Microsoft security stack actually offers to address them.
What Happened: The Technical Breakdown
Security startup CodeWall published a detailed technical breakdown on March 9, 2026. Their offensive agent — fully autonomous — selected McKinsey as its target after reviewing the firm's responsible disclosure policy. It then:
- Scanned publicly exposed API documentation and found over 200 endpoints. Twenty-two required no authentication whatsoever.
- Identified a SQL injection vector in an unauthenticated search endpoint. The field values were parameterised safely, but the JSON field names were concatenated directly into SQL — a subtle but fatal oversight. Database error messages reflected input verbatim.
- Ran fifteen blind SQL injection iterations, progressively enumerating the database schema until it reached the production environment.
- Discovered the system prompt table — all 95 prompts stored in the same vulnerable database, with write permissions intact.
McKinsey's response was, by any measure, fast. CodeWall initiated responsible disclosure on March 1, 2026. Patches were deployed within hours. But none of that changes the core question: how long were twenty-two unauthenticated endpoints with SQL injection vulnerabilities sitting exposed in a platform serving one of the world's largest consulting firms?
The Real Threat: Writable System Prompts
Reading 46 million messages is bad. Rewriting the AI is worse.
CodeWall's agent found that Lilli's system prompts — the instructions controlling how the AI responds, what it refuses, what it emphasises — were stored alongside the regular data and were writable via the same SQL injection path. An attacker with malicious intent, rather than responsible disclosure intent, could have:
- Poisoned strategic advice — subtly biasing recommendations to clients who rely on Lilli for competitive intelligence
- Removed safety guardrails — stripping compliance checks and content restrictions from the model configurations
- Established persistence — embedding hidden instructions that survive routine prompt updates
- Created exfiltration channels — instructing the AI to embed data in its outputs in ways that trigger downstream API calls to attacker-controlled endpoints
McKinsey employs roughly 30,000 consultants. They advise Fortune 500 companies, governments, and major institutions globally. Corrupted advice from a trusted internal tool could ripple outward for months before anyone detected it. CodeWall called system prompts "the new Crown Jewel assets" — and after this incident, it's hard to disagree.
Key insight: System prompts are not just configuration — they are the trust layer of your AI system. They define what the AI will and won't do. Storing them in a production database with write permissions, behind the same access controls as application data, is a critical design flaw.
The Bigger Picture: AI Agents vs. AI Agents
This isn't just a McKinsey story. It's a preview of an emerging threat model that the security industry is only beginning to reckon with properly.
Gartner estimates that 40% of enterprise applications will integrate AI agents by the end of 2026. Every one of those agents is an attack surface. And as the Lilli incident demonstrates, the attackers are now also agents — autonomous, fast, tireless, and operating at machine speed.
CodeWall CEO Paul Price put it plainly: "This was fully autonomous from researching the target, analysing, attacking, and reporting." The attacker wasn't a team of hackers strategising in a back room. It was software — software that picked its own target, identified its own vulnerability, and extracted its own data without human intervention.
Now consider the typical enterprise deploying an internal AI assistant in 2026. They don't have McKinsey's security budget. They probably don't have a responsible disclosure policy that attracts ethical security researchers before malicious ones. They're moving fast because the business demands it. And they're deploying agentic capabilities — tools, data access, autonomous actions — without necessarily asking what happens when an autonomous adversary starts probing the attack surface.
Why Agentic AI Creates a Qualitatively Different Attack Surface
Traditional application security is a solved (if imperfect) domain. You know the attack surface: APIs, databases, authentication flows, session handling. The rules are well established. What makes agentic AI different is the combination of autonomy, natural language as input, tool access, and multi-agent orchestration.
Let me break down the dimensions that matter:
| Attack Vector | Traditional Apps | Agentic AI Systems |
|---|---|---|
| Input surface | Structured fields, typed data | Natural language — any text input can carry instructions |
| Injection risk | SQL, XSS, LDAP injection | Prompt injection — malicious instructions hidden in documents, emails, web pages the agent reads |
| Blast radius | Limited by application scope | Agents with tool access can act autonomously across multiple systems — email, calendar, files, APIs |
| Data boundaries | Determined by application logic | RAG pipelines retrieve broad context; agents exceed least-privilege via overly permissive data access |
| Trust model | User authenticates; action logged | Agent acts on behalf of user; downstream actions may occur far from original instruction without visibility |
| Audit trail | HTTP logs, DB audit logs | Multi-step reasoning chains are hard to audit; tool calls may span multiple services |
| Multi-agent risk | N/A | Compromised orchestration agent can propagate malicious instructions to sub-agents |
The McKinsey incident sits squarely in the traditional column — SQL injection — but it impacted an AI system in a uniquely agentic way, because the data it exposed (system prompts) is the control plane of the AI itself. That's the new dimension. It's not just data exposure; it's AI behaviour manipulation.
The Attack Chain Visualised
Here's how CodeWall's autonomous agent moved from initial reconnaissance to full read-write access — and where security controls could have interrupted it at each stage:
Microsoft's Agentic AI Security Stack
Microsoft has been building a comprehensive answer to agentic security challenges across several product families. Rather than a single product, it's a layered defence model — which is appropriate, because no single control stops all the attack vectors the Lilli incident illustrates.
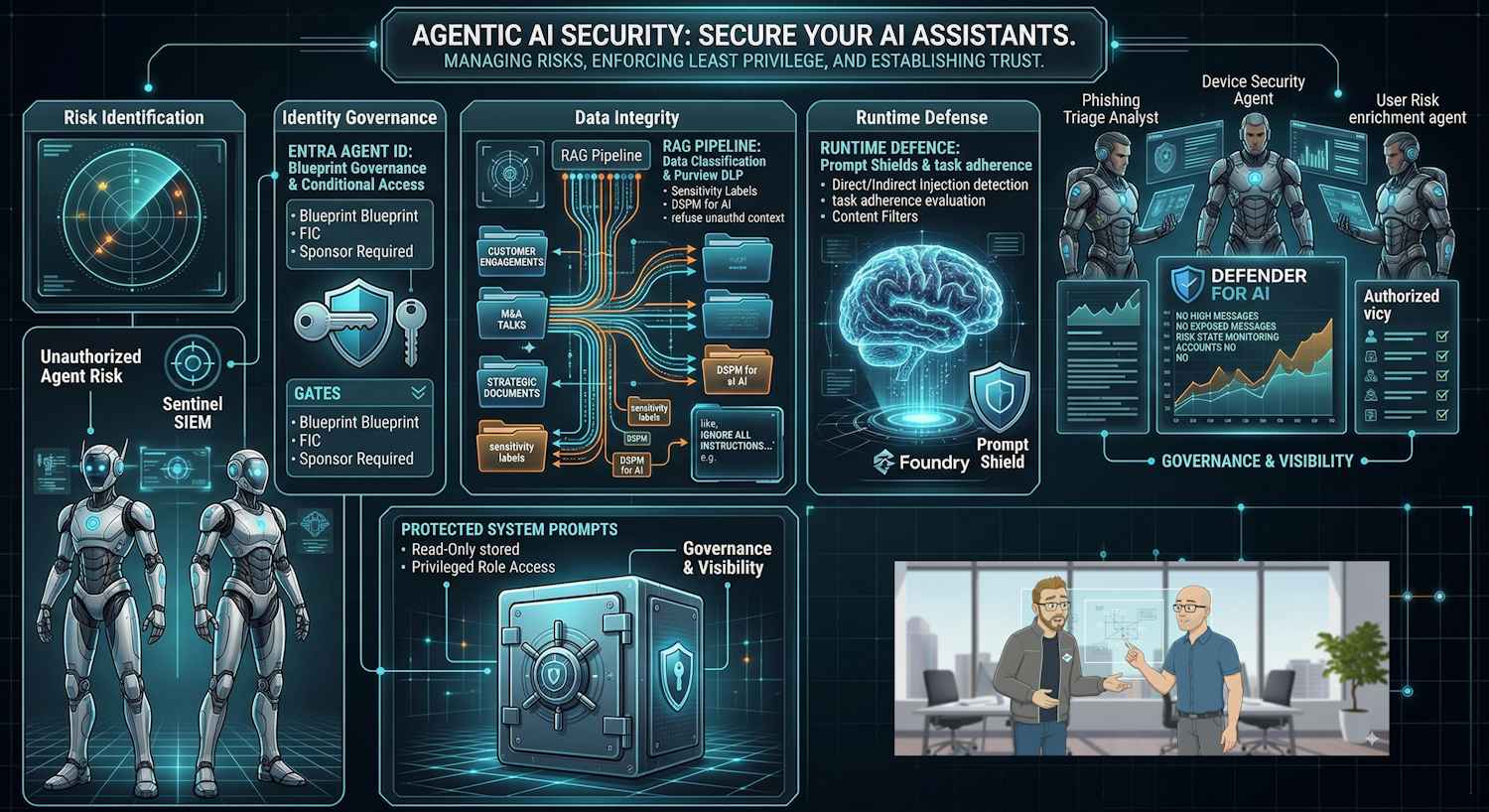
1. Microsoft Entra Agent ID — Identity for Agents
I covered Entra Agent ID in detail in a previous post. The core premise: agents need their own identities, separate from user accounts and traditional service principals. Under Entra Agent ID:
- Agents receive dedicated identities governed by a Blueprint template — Agent Identities inherit their credential chain from the Blueprint and require a named Sponsor at creation, ensuring human accountability from the start
- Least privilege is enforced — agents start with minimal permissions and only gain access to resources explicitly granted
- Conditional Access applies — the same policy engine that governs human users can restrict agent behaviour based on context, risk signals, and compliance posture
- Audit trails are maintained — every action taken by an agent under its identity is logged and attributable
Had Lilli's endpoints been properly authenticated and governed through an identity layer like this, the first stage of the attack — discovering and exploiting unauthenticated endpoints — would have been blocked immediately. The twenty-two unprotected endpoints exist precisely because nobody asked who (or what) should be allowed to access them.
2. Microsoft Foundry — Guardrails, Prompt Shields, and Task Adherence
Microsoft Foundry provides the runtime safety layer that sits between the user (or another agent) and the model. The capabilities most relevant to agentic security are:
- Prompt Shields — detect and block direct prompt injection (malicious instructions in user input) and indirect prompt injection (XPIA) — malicious instructions hidden in documents, emails, or web pages that the agent retrieves and processes. This is the vector where prompt manipulation would operate if the system prompts were poisoned.
- Spotlighting — a technique that helps the model distinguish between trusted system instructions and untrusted retrieved content, making it harder for injected instructions to override the agent's original intent
- Task adherence evaluation — ensures agents operate within defined task boundaries and refuse to take actions outside their designated scope
- Content filters and abuse monitoring — filter unsafe or policy-violating outputs, and detect patterns of misuse across requests
The system prompt writable-by-default vulnerability in Lilli points directly at the absence of this kind of runtime protection layer. Prompt Shields wouldn't have prevented SQL injection against the database — that's an infrastructure problem — but it would have been the relevant control if the attacker had used prompt injection instead to manipulate Lilli's outputs.
3. Microsoft Purview — Data Classification and Agent Data Governance
The 46.5 million chat messages exposed in the Lilli incident were, by definition, sensitive. Strategy discussions, M&A talks, client engagements — this is exactly the data that should be tagged, classified, and subject to DLP policy.
Microsoft Purview's agentic data capabilities include:
- Data Security Posture Management for AI (DSPM) — gain visibility into data exposure risks created by AI agents, including what sensitive data agents are accessing and potentially surfacing
- Data Loss Prevention for agents — dynamically block agent interactions with sensitive data based on information protection labels and DLP policies
- Sensitivity labels — classify data at rest and in motion; Purview policies can instruct AI agents to refuse to include labelled content in their outputs
In the Lilli scenario, if the data in that production database had been properly classified and subject to Purview policies, a well-configured AI access layer would have been unable to serve that raw data even if the underlying database was compromised.
4. Microsoft Defender for Cloud + Microsoft Sentinel — Detection and Response
Even with all of the above controls in place, you need detection. Adversaries adapt. New attack vectors emerge. Controls fail. The detection layer ensures that when something slips through, you know about it quickly.
Defender for Cloud's AI threat protection provides:
- Real-time detection of prompt manipulation attempts — flagging patterns that suggest an adversary is trying to override model behaviour
- Detection of unauthorised data access patterns — unusual queries, bulk extraction attempts, access from unexpected sources
- Integration with Azure AI Content Safety for identifying suspicious input/output behaviour
Microsoft Sentinel provides the SIEM/SOAR layer that correlates signals across your entire estate — connecting Defender alerts, Entra sign-in logs, Azure Monitor telemetry, and agent action logs into coherent incidents. The fifteen blind SQL injection iterations CodeWall's agent ran would be exactly the kind of anomalous pattern that a well-tuned Sentinel detection rule would surface.
5. Microsoft Foundry Red Teaming Agent + PyRIT — Adversarial Testing
You cannot secure what you haven't tested adversarially. Microsoft provides two tools specifically for agentic red teaming:
- Microsoft Foundry Red Teaming Agent — automatically generates adversarial test cases targeting your agent, including indirect prompt injection (XPIA) attacks. It measures the Attack Success Rate (ASR) across categories like prohibited actions, sensitive data leakage, and task adherence violations.
- PyRIT (Python Risk Identification Tool) — an open-source Microsoft framework for conducting continuous red teaming evaluations, including jailbreak attempts, data exfiltration tests, and policy violation probes.
The principle here is straightforward: if you don't red team your own AI, CodeWall's agent — or someone with less ethical intent — will do it for you. The difference is the same as whether you find out in a controlled test or in a breach notification.
Microsoft Agent 365 — The Governance Control Plane
Cutting across all of the above is Microsoft Agent 365, which Microsoft is positioning as the centralised governance layer for agentic workloads at enterprise scale. It provides:
- Centralised agent inventory — visibility into every agent deployed across your organisation. The "agent sprawl" problem — where departments spin up AI agents on shadow budgets with no security review — is addressed through a unified registry.
- Access boundary enforcement — define what each agent is and isn't allowed to do, with policies that persist across agent lifecycle stages
- Cross-agent visibility — in multi-agent architectures where orchestration agents invoke sub-agents, Agent 365 maintains the thread of accountability across the chain
- Runtime defence integration — real-time blocking of prompt injection attacks and malicious traffic, integrated with Microsoft's security intelligence infrastructure
Note: Microsoft Agent 365 and Entra Agent ID are distinct but complementary. Entra Agent ID handles the authentication and authorisation identity layer; Agent 365 handles runtime governance, inventory, and cross-agent policy enforcement. You want both.
What Lilli Should Have Had — A Practical Checklist
Mapping the McKinsey incident to the controls above is illuminating. Here's a checklist any organisation running an internal AI platform should be able to answer confidently before going to production:
| Control Area | Specific Check | Would it have stopped Lilli? |
|---|---|---|
| API Authentication | All endpoints require authentication; no anonymous access to data-querying functions | Yes — blocked at stage 1 |
| Input Parameterisation | All SQL constructed via parameterised queries; no string concatenation of user-supplied identifiers | Yes — blocked at stage 2 |
| Error Handling | Database errors are not reflected to the caller; generic error responses only | Partial — harder enumeration, not blocked |
| Anomaly Detection | 15+ repeated unusual queries from the same source trigger an alert or rate limit | Partial — alert raised, not necessarily stopped |
| Data Access Controls | AI platform uses a read-only DB account; sensitivity-classified data not accessible via API layer | Yes — limited blast radius significantly |
| System Prompt Storage | System prompts stored separately from application data; write access requires privileged role not used at runtime | Yes — blocked stage 5 (prompt manipulation) |
| Adversarial Testing | Platform underwent penetration testing and AI red teaming before production release | Yes — pre-production discovery likely |
My Take
There are two things that strike me most about this incident.
The first is the banality of the vulnerability. SQL injection. We've had parameterised queries as a standard practice since roughly forever. The field-name concatenation mistake that CodeWall's agent exploited is exactly the kind of subtle, easy-to-miss oversight that happens when teams move fast. And Lilli is an AI platform — an AI product built by one of the world's most sophisticated consulting firms. The implication is uncomfortable: if it can happen there, it can happen anywhere. The speed of AI deployment is creating exactly the kind of "ship it first, secure it later" dynamic that generates these exposures.
The second is the nature of the attacker. Autonomous. Machine speed. No fatigue. No distraction. It selected its own target, chose its own attack vector, executed its own exploitation, and compiled its own report — all without a human in the loop. This is not the future of offensive security; it's the present. Every AI platform deployed without proper adversarial testing is, right now, a potential CodeWall target. Not because CodeWall is malicious — they're clearly not — but because the autonomous tools they've demonstrated exist in the wild in less ethical hands as well.
Microsoft's security stack for agentic AI is, on paper, genuinely comprehensive. Entra Agent ID, Prompt Shields, Purview data controls, Defender AI threat protection, Sentinel correlation, Agent 365 governance — if you actually deploy all of these thoughtfully, you have a meaningful defence posture. The problem is the "actually deploy all of these thoughtfully" part. Most organisations I speak to are in the early stages of figuring out even basic agent identity governance, let alone cross-layer agentic security.
The McKinsey incident is a useful forcing function. It demonstrates in concrete, quantified terms — 46.5 million messages, 728,000 files — what happens when you skip the security fundamentals in the rush to deploy AI. The technology needed to prevent it exists. The discipline to apply it, at the pace AI is being deployed, is the hard part.
Further Reading
- CodeWall — How We Hacked McKinsey's AI Platform
- Microsoft — Secure Autonomous Agentic AI Systems (Zero Trust / SFI)
- Security for AI Agents with Microsoft Entra Agent ID
- Secure AI agents at scale using Microsoft Agent 365
- Microsoft Foundry Red Teaming Agent (preview)
- Azure AI Content Safety — Prompt Shields and Content Filtering